文档/图片表格公式识别
PDF翻译与转换的AI
全方位解决方案: Doc2X
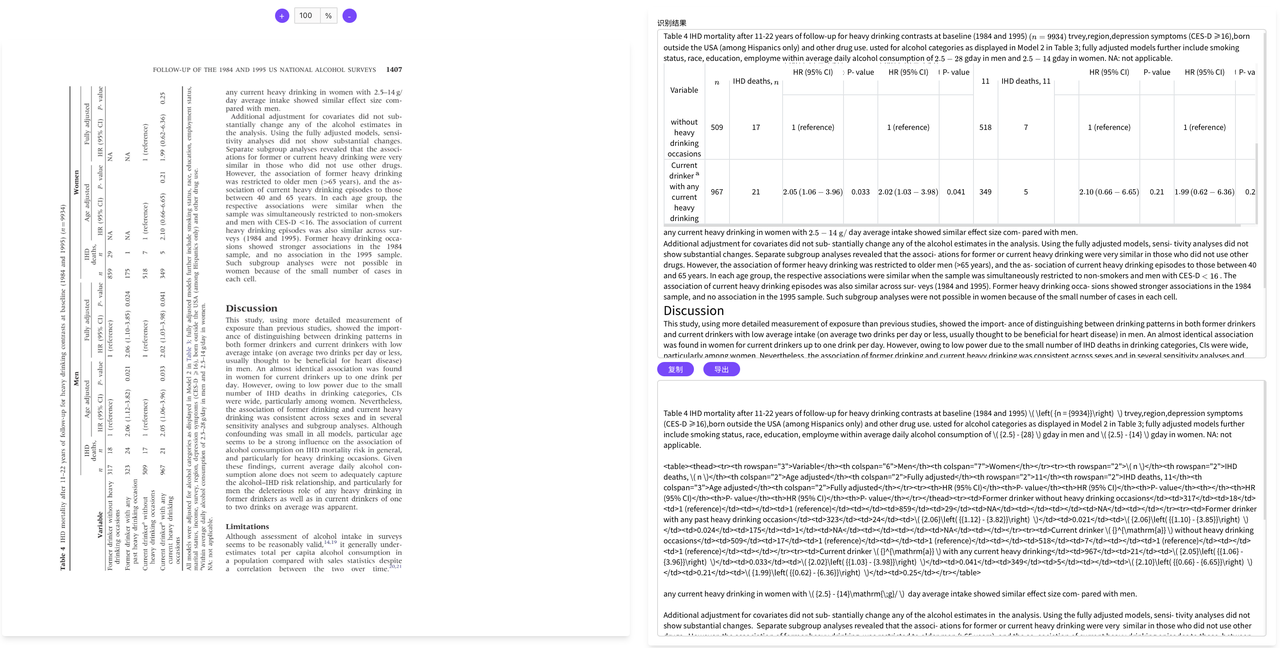
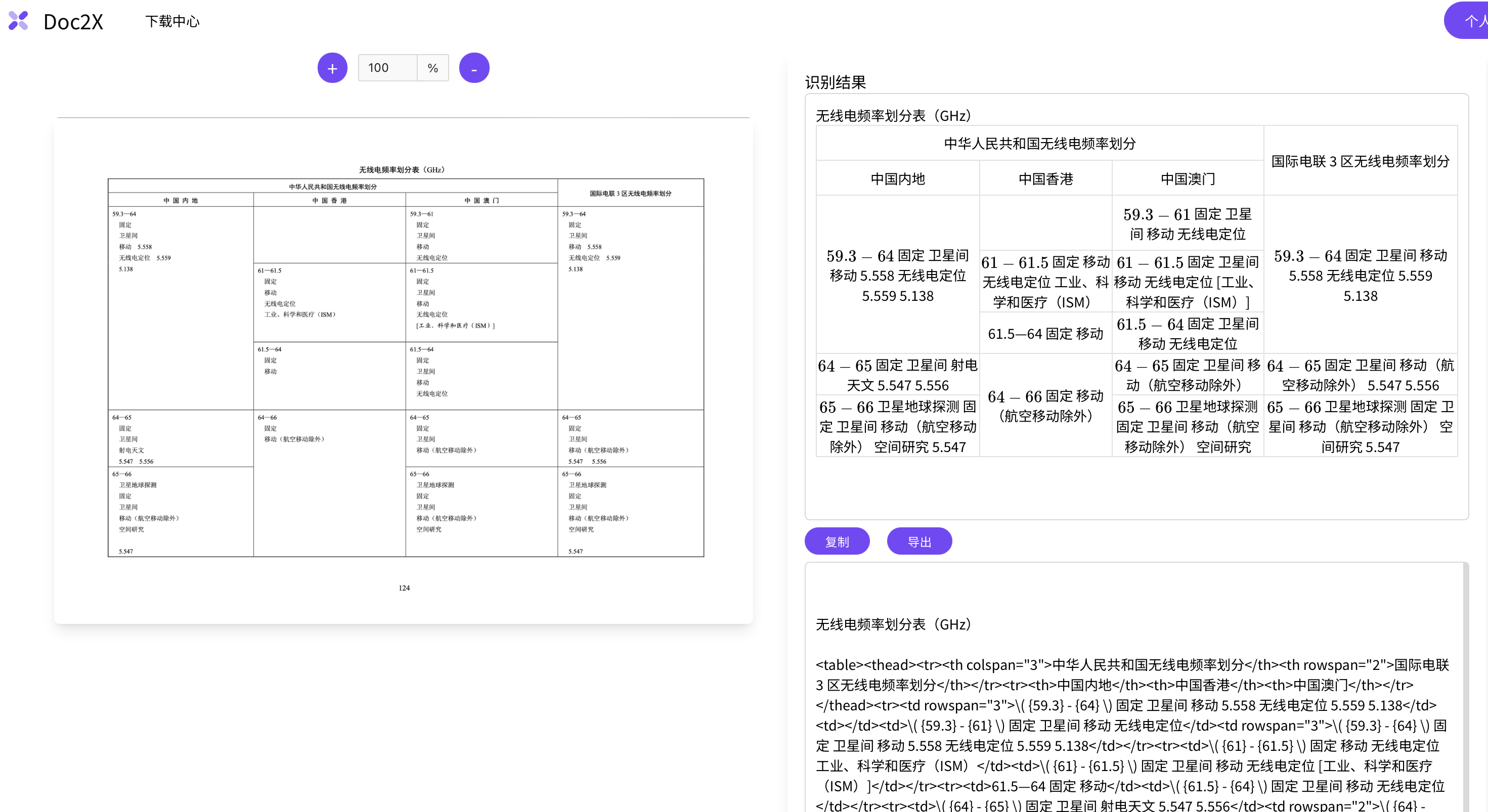
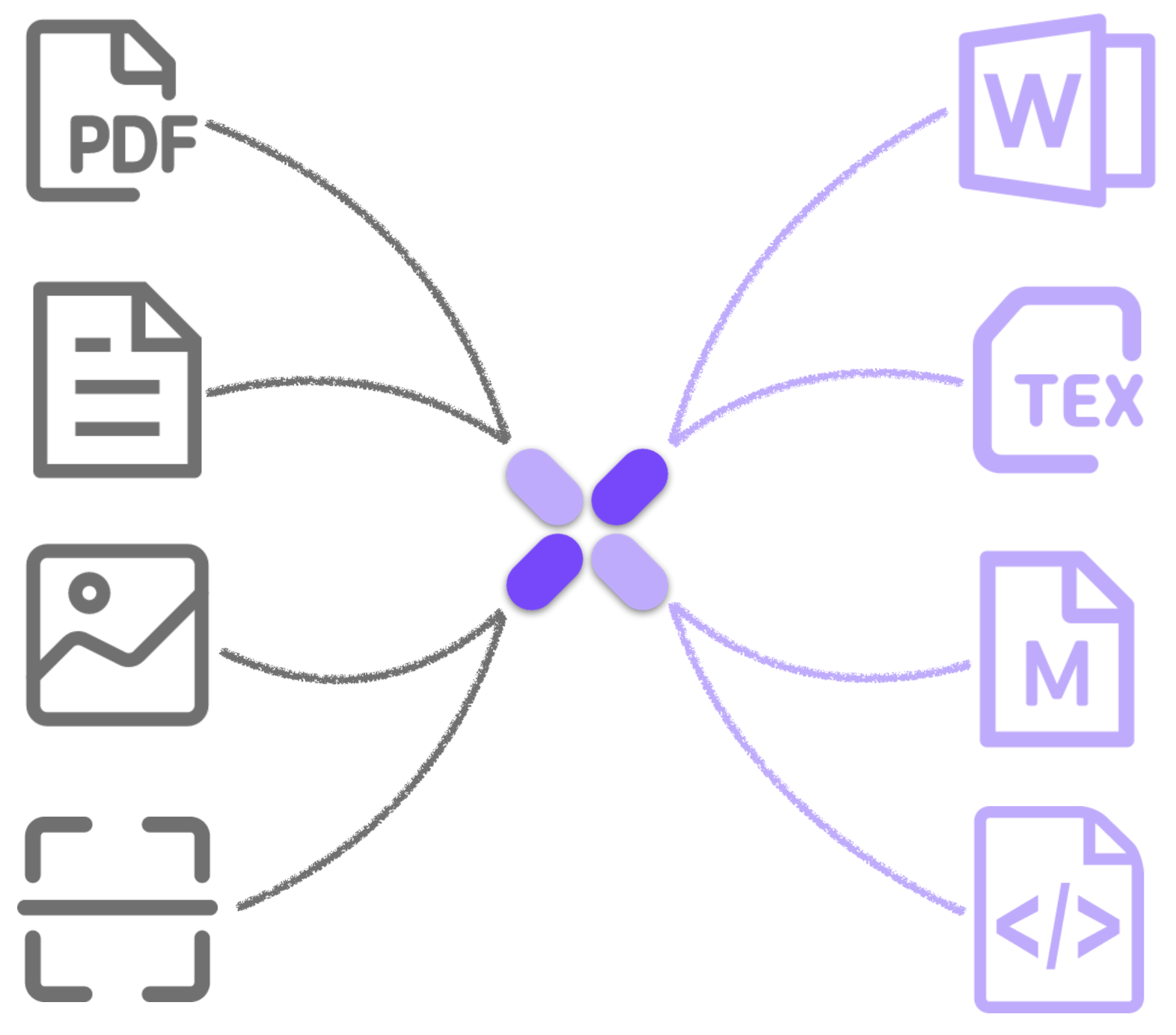
AI驱动的智能解析技术,无论是学术科研论文、教辅书籍、企业文档、国家标准还是财报研报等都能精准识别PDF中的表格和公式,一键转换为Word、LaTeX、HTML、Markdown等格式,支持多语言PDF翻译与双语对照。轻松实现文档结构化,立即体验高效智能的文档处理工作流!
听听用户声音
多家高校、研究机构、出版社、媒体与企业通过Doc2X提升工作效率与信息利用价值

交流群用户
高校学生
“沉浸式翻译好多钱买个年费最后也是导PDF看着更舒服一点,但是他们的公式都是图片格式的,表格什么的也处理的不好,这波直接被爆杀,成本降低100倍”
Jack_Plus刘老师
教育培训从业者
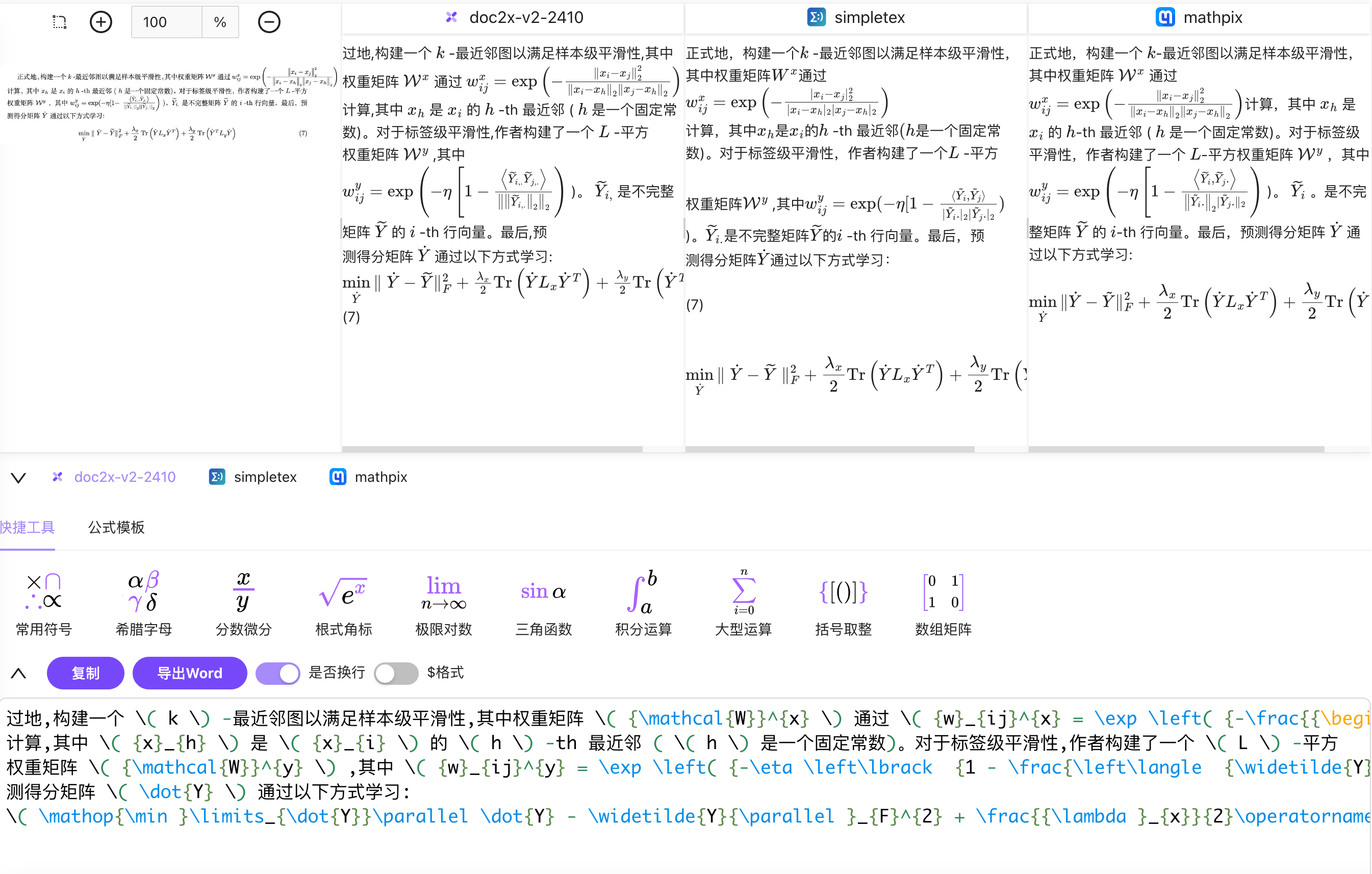
“识别准确度很高,与mathpix旗鼓相当,国产AI很给力!”
华中科技大学某课题组
科研团队
“论文数据整理时间缩短一半,公式与表格识别极其准确。”